I have a confession to make…
I love C90.
Yes, I said it. Strict, pedantic ISO C90 – also known as ANSI C. You might be wondering why I support a 30+ year old standard. You might even be wondering why you ever started following website in the first place. But before you start telling me how wrong I am, let me explain myself. When using strict ISO C90, I feel like it will force me to produce more portable, robust and clean code than say using the C99 standard. I also like to think that if I use the most mature standard, the compiler will also be more mature, more stable, quicker and produce better machine code (the man pages for gcc v4.8.2 still say C99 is only partially supported). Many of the most stringent coding standards used in high reliability/safety critical systems only support ANSI C. There could be many reasons for this – legacy code, legacy compilers, etc… But to be quite honest, my love for ISO C90 is partly (if not mostly) in my head. C99 introduced a wide variety of new features to the C programming language. A lot of them are actually good, if not great. But others are just dangerous and can’t be justified in my opinion and for this reason I stay away from the newer standard as much as possible.
But no more. I will [try to] embrace its positive aspects. Over the course of this mini-series, I will show you examples of both the good and the bad of C99. Hopefully at the end of it, we will come to the conclusion that if used correctly, the C99 standard can help in writing more clear, robust and optimized code than with C90.
One side note here before we get started. Whether you are using C90 or C99, it is highly recommended to disable compiler specific constructs and extensions when possible. There are times when they are needed, but their use should be limited to hardware specific code and should not be scattered around in every source file. Try porting code that randomly assigns variables to hardcoded memory locations to a different hardware platform…
Now, let’s get started shall we?
Round 1: Initialization of complex data types
The first difference between C90 and C99 we will explore is the initialization of complex data types within a function. A complex data type is an array, structure or union. In C90, all initializers of complex data type must be constant expressions. A constant expression is one that can be evaluated at compile time. This means for example, you cannot pass in an argument as an initializer. Similarly, a function call cannot be used as an initializer. In C99, both of these are possible. This is a very useful feature in many circumstances. Let’s say you have a driver for a command based device (think SPI NOR). You write a small helper function to support a specific command which requires one address byte and one data byte following the command (three bytes in total assuming 8-bit commands). The address and data are passed as arguments by the calling function. Let’s take a look at how we have to do this in C90.
int spi_nor_cmd_xxx (uint8_t address, uint8_t data)
{
uint8_t cmd[3];
cmd[0] = 0x50; /* Don't use magic numbers !! */
cmd[1] = address;
cmd[2] = data;
return spi_nor_write(cmd, sizeof(cmd));
}
So what is wrong with that? Technically, nothing at all (other than the magic number 🙂 it’s only there to show it is constant). But there are three points I would consider which would make this better.
- The array cmd could be defined as a constant. Once initialized, it should never change.
- The array is initialized with a defined length of three (3) rather than allowing the compiler to determine the length based on the number of initializers. This could lead to copy-paste errors if multiple of these helper functions are implemented (yes… I shouldn’t have used magic numbers either).
- It takes 4 lines of code to initialize this three byte command.
All three of these points can be addressed by using C99 and its support for non-constant initializers.
int spi_nor_cmd_xxx (uint8_t address, uint8_t data)
{
const uint8_t cmd[] = {0x50, address, data};
return spi_write(cmd, sizeof(cmd));
}
That looks much better in my opinion. With the C99 version, the array is now constant and it is defined in a single line. There is less room for error because the array size is defined based on the number of initializers.
An important factor which must be considered: does this affect the output? Is there any change in performance, memory usage, ability to optimize? I would assume not considering it is really the exact same code functionally, however this could vary by compiler. I tested this theory using gcc v4.8.2 (x86) on Linux. I chose to compile for x86 instead of the usual msp430 because I figured since x86 assembly is vastly more complex, if there is anyway to optimize one over the other, it would do so. To compile with strict C90 enabled and all GNU extensions disabled, the command line arguments ‘-ansi -Wpedantic’ must be used. The ‘-ansi’ argument is equivalent to ‘-std=c90’ in gcc. The ‘-Wpedantic’ flag tells the compiler that it must check for strict ISO compliance. Compiling the C90 version of code produces the output below (using objdump).
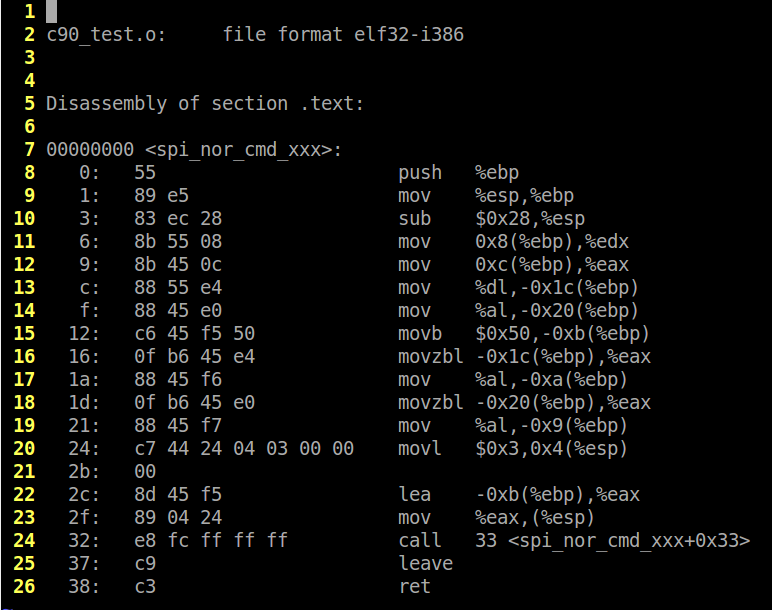
Compiling the C99 version with ‘-std=c99’ to enable C99 but not the GNU extensions produces the output below.
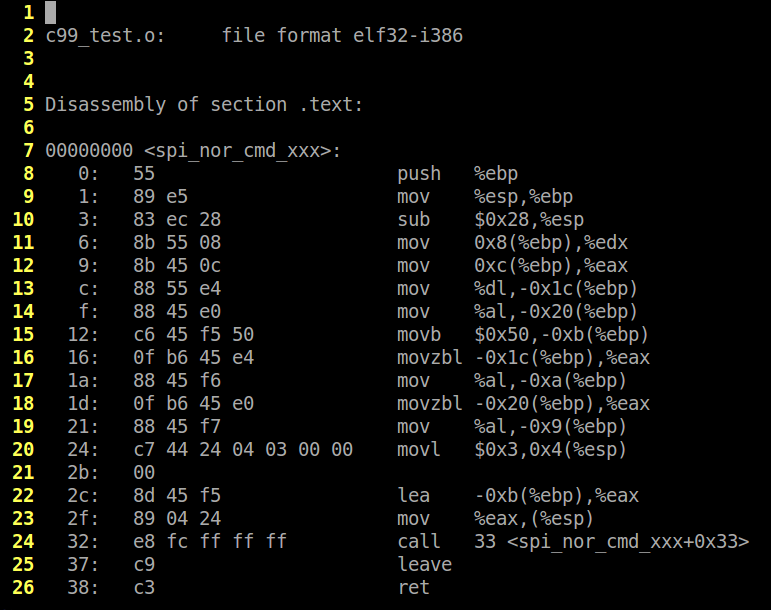
Comparing the two we can see that they are exactly the same. Compiling again with optimizations set to O2 shows no difference. Compiling once more with msp430-gcc shows the same results. Interestingly enough, msp430-gcc produced more efficient code than x86-gcc in terms of code size / number of operations – guess my hypothesis was wrong. This is by no means an exhaustive set of tests but it shows that the compiler recognizes these two examples as two different forms of the same construct. However, this is a very simple example, and if you had more variables and code which might change the order of execution, the output will undoubtedly change as well.
Can you think of any downsides to the C99 form? Potentially. Let’s say one of the initializers was a function call which returns a uint8_t. If the function call can fail and return an error instead of a valid value (as it should), then I would not recommend this approach. Instead the function should be called first, the return value checked, and then if and only if it is sane, the command can be initialized. The wrong/dangerous way:
int spi_nor_cmd_xxx (uint8_t data)
{
const uint8_t cmd[] = {0x50, saved_data_get_address(), data};
return spi_write(cmd, sizeof(cmd));
}
The better way:
int spi_nor_cmd_xxx (uint8_t data)
{
int err = -1;
const uint8_t address = saved_data_get_address(0);
if (address > 0) {
const uint8_t cmd[] = {0x50, address, data};
err = spi_write(cmd, sizeof(cmd));
}
return err;
}
What about all these new stack variables I just allocated? Isn’t that less efficient? Well maybe, but the compiler should easily optimize all that out. Plus, if you were to implement the same code in C90 correctly, you would have the exact same issue. So yes, here with C99 we could have written more concise code (although arguably maybe more difficult to read), however it would not meet our standards for error checking. So use this feature wisely.
Keep in mind that all this applies to the initialization of structures as well. Say we have a similar example as above, but instead of a byte array being written to a device, the command is a message which is going to be queued for use by a different code module.
struct message
{
uint8_t cmd;
uint8_t address;
uint8_t data;
};
Again, we want to make a simple helper function to send a specific message. In C90, it would look like this:
int send_message_xxx(uint8_t address, uint8_t data)
{
struct message msg;
msg.cmd = 0x50; /* Don’t use magic numbers !! */
msg.address = address;
msg.data = data;
send_message(&msg);
}
Ok, not all that bad. Let’s see how it looks with C99.
int send_message_xxx(uint8_t address, uint8_t data)
{
const struct message msg = {0x50, address, data};
return send_message(&msg);
}
As with the example using arrays, the C99 version of this code is cleaner, more concise and allows us to define the message as a constant. However, this type of initialization for structures can be dangerous. If my colleague adds a new member to the structure right after cmd, the initialization code in C99 would be wrong. But as we all know, this a general problem with initializing structures in C. If the structure was initialized outside a function, you don’t even have the option of explicitly assigning the initializers. With C90 at least…
In the next round of Battle of the Standards, we will see that C99 addresses this issue quite elegantly. But for today, I conclude that initializing complex data types with non-constant initializers is a feature of C99 which I certainly accepted in my toolkit. It has a few key benefits, and virtually no pitfalls. +1 for C99.